Vocab Diet: Reshaping the Vocabulary of LLMs with Vector Arithmetic
Large language models (LLMs) were shown to encode word form variations, such as "walk"->"walked", as linear …
Context Length Alone Hurts LLM Performance Despite Perfect Retrieval
Large language models (LLMs) often fail to scale their performance on long-context tasks performance in line with the context lengths …

How Quantization Shapes Bias in Large Language Models
This work presents a comprehensive evaluation of how quantization affects model bias, with particular attention to its impact on …
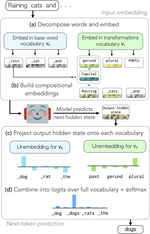
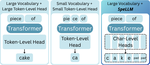
SpeLLM: Character-Level Multi-Head Decoding
Scaling LLM vocabulary is often used to reduce input sequence length and alleviate attention's quadratic cost. Yet, current LLM …
Don’t Overthink it. Preferring Shorter Thinking Chains for Improved LLM Reasoning
Reasoning large language models (LLMs) heavily rely on scaling test-time compute to perform complex reasoning tasks by generating …

Follow the Flow: On Information Flow Across Textual Tokens in Text-to-Image Models
Text-to-Image (T2I) models often suffer from issues such as semantic leakage, incorrect feature binding, and omissions of key concepts …
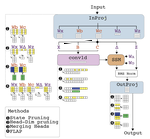
On Pruning State-Space LLMs
Recent work proposed state-space models (SSMs) as an efficient alternative to transformer-based LLMs. Can these models be pruned to …
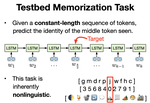
From Tokens to Words: on the Inner Lexicon of LLMs
Natural language is composed of words, but modern LLMs process sub-words as input. A natural question raised by this discrepancy is …
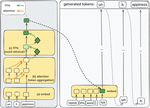
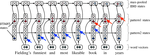
Attend First, Consolidate Later: On the Importance of Attention in Different LLM Layers
In decoder-based LLMs, the representation of a given layer serves two purposes: as input to the next layer during the computation of …
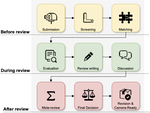
What Can Natural Language Processing Do for Peer Review?
The number of scientific articles produced every year is growing rapidly. Providing quality control over them is crucial for scientists …
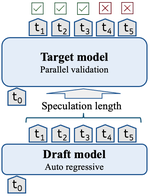
Accelerating Speculative Decoding using Dynamic Speculation Length
Speculative decoding is a promising method for reducing the inference latency of large language models. The effectiveness of the method …
The Larger the Better? Improved LLM Code-Generation via Budget Reallocation
It is a common belief that large language models (LLMs) are better than smaller-sized ones. However, larger models also require …
Beyond Performance: Quantifying and Mitigating Label Bias in LLMs
Large language models (LLMs) have shown remarkable adaptability to diverse tasks, by leveraging context prompts containing …

Transformers are Multi-State RNNs
Transformers are considered conceptually different from the previous generation of state-of-the-art NLP models—recurrent neural …
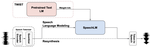
Textually Pretrained Speech Language Models
Speech language models (SpeechLMs) process and generate acoustic data only, without textual supervision. In this work, we propose …
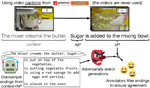
Breaking Common Sense: WHOOPS! A Vision-and-Language Benchmark of Synthetic and Compositional Images
Weird, unusual, and uncanny images pique the curiosity of observers because they challenge commonsense. For example, an image released …

Read, Look or Listen? What’s Needed for Solving a Multimodal Dataset
The prevalence of large-scale multimodal datasets presents unique challenges in assessing dataset quality. We propose a two-step method …

Surveying (Dis)Parities and Concerns of Compute Hungry NLP Research
Many recent improvements in NLP stem from the development and use of large pre-trained language models (PLMs) with billions of …

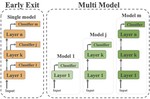
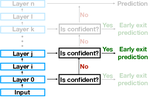
Finding the SWEET Spot: Analysis and Improvement of Adaptive Inference in Low Resource Settings
Adaptive inference is a simple method for reducing inference costs. The method works by maintaining multiple classifiers of different …
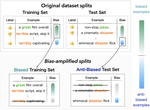
Fighting Bias with Bias: Promoting Model Robustness by Amplifying Dataset Biases
NLP models often rely on superficial cues known as dataset biases to achieve impressive performance, and can fail on examples where …
Curating Datasets for Better Performance with Example Training Dynamics
The landscape of NLP research is dominated by large-scale models training on colossal datasets, relying on data quantity rather than …
Morphosyntactic Probing of Multilingual BERT Models
We introduce an extensive dataset for multilingual probing of morphological information in language models (247 tasks across 42 …
VASR: Visual Analogies of Situation Recognition
A core process in human cognition is analogical mapping: the ability to identify a similar relational structure between different …

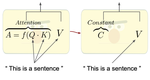
How Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers
The attention mechanism is considered the backbone of the widely-used Transformer architecture. It contextualizes the input by …
Efficient Methods for Natural Language Processing: A Survey
Recent work in natural language processing (NLP) has yielded appealing results from scaling model parameters and training data; …
WinoGAViL: Gamified Association Benchmark to Challenge Vision-and-Language Models
While vision-and-language models perform well on tasks such as visual question answering, they struggle when it comes to basic human …

Fewer Errors, but More Stereotypes? The Effect of Model Size on Gender Bias
The size of pretrained models is increasing, and so does their performance on a variety of NLP tasks. However, as their memorization …
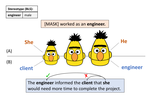
TangoBERT: Reducing Inference Cost by using Cascaded Architecture
The remarkable success of large transformer-based models such as BERT, RoBERTa and XLNet in many NLP tasks comes with a large increase …
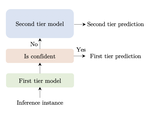
On the Limitations of Dataset Balancing: The Lost Battle Against Spurious Correlations
Recent work has shown that deep learning models in NLP are highly sensitive to low-level correlations between simple features and …
Measuring the Carbon Intensity of AI in Cloud instances
The advent of cloud computing has provided people around the world with unprecedented access to computational power and enabled rapid …

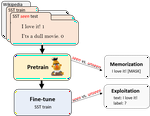
Data Contamination: From Memorization to Exploitation
Pretrained language models are typically trained on massive web-based datasets, which are often “contaminated” with downstream test …
ABC: Attention with Bounded-memory Control
Transformer architectures have achieved stateof-the-art results on a variety of natural language processing (NLP) tasks. However, their …
Expected Validation Performanceand Estimation of a Random Variable’s Maximum
NLP is often supported by experimental results, and improved reporting of such results can lead to better understanding and more …
Effects of Parameter Norm Growth During Transformer Training: Inductive Bias from Gradient Descent
The capacity of neural networks like the widely adopted transformer is known to be very high. Evidence is emerging that they learn …
Data Efficient Masked Language Modeling for Vision and Language
Masked language modeling (MLM) is one of the key sub-tasks in vision-language pretraining. In the cross-modal setting, tokens in the …

Provable Limitations of Acquiring Meaning from Ungrounded Form: What will Future Language Models Understand?
Language models trained on billions of tokens have recently led to unprecedented results on many NLP tasks. This success raises the …
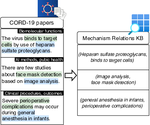
Extracting a Knowledge Base of Mechanisms from COVID-19 Papers
The urgency of mitigating COVID-19 has spawned a large and diverse body of scientific literature that is challenging for researchers to …
Automatic Generation of Contrast Sets from Scene Graphs: Probing the Compositional Consistency of GQA
Recent works have shown that supervised models often exploit data artifacts to achieve good test scores while their performance …

Random Feature Attention
Transformers are state-of-the-art models for a variety of sequence modeling tasks. At their core is an attention function which models …

Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics
Large datasets have become commonplace in NLP research. However, the increased emphasis on data quantity has made it challenging to …

Extracting a knowledge base of mechanisms from COVID-19 papers
The COVID-19 pandemic has sparked an influx of research by scientists worldwide, leading to a rapidly evolving corpus of …
The Right Tool for the Job: Matching Model and Instance Complexities
As NLP models become larger, executing a trained model requires significant computational resources incurring monetary and …
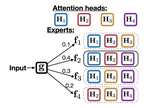
A Mixture of h-1 Heads is Better than h Heads
Multi-head attentive neural architectures have achieved state-of-the-art results on a variety of natural language processing tasks. …
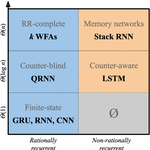
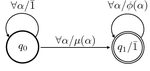
A Formal Hierarchy of RNN Architectures
We develop a formal hierarchy of the expressive capacity of RNN architectures. The hierarchy is based around two formal properties: …
Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping
Fine-tuning pretrained contextual word embedding models to supervised downstream tasks has become commonplace in natural language …
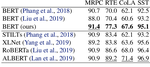
Show Your Work: Improved Reporting of Experimental Results
Research in natural language processing proceeds, in part, by demonstrating that new models achieve superior performance (e.g., …
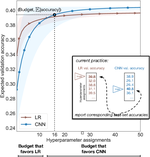
RNN Architecture Learning with Sparse Regularization
Neural models for NLP typically use large numbers of parameters to reach state-of-the- art performance, which can lead to excessive …
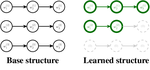
PaLM: A Hybrid Parser and Language Model
We present PaLM, a hybrid parser and neural language model. Building on an RNN language model, PaLM adds an attention layer over text …

Knowledge Enhanced Contextual Word Representations
Contextual word representations, typically trained on unstructured, unlabeled text, do not contain any explicit grounding to real world …
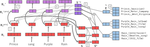

Inoculation by Fine-Tuning: A Method for Analyzing Challenge Datasets
Several datasets have recently been constructed to expose brittleness in models trained on existing benchmarks. While model performance …

Rational Recurrences
Despite the tremendous empirical success of neural models in natural language processing, many of them lack the strong intuitions that …
SoPa: Bridging CNNs, RNNs, and Weighted Finite-State Machines
Recurrent and convolutional neural networks comprise two distinct families of models that have proven to be useful for encoding natural …
LSTMs Exploit Linguistic Attributes of Data
While recurrent neural networks have found success in a variety of natural language processing applications, they are general models of …
Annotation Artifacts in Natural Language Inference Data
Large-scale datasets for natural language inference are created by presenting crowd workers with a sentence (premise), and asking them …

A Dataset of Peer Reviews (PeerRead): Collection, Insights and NLP Applications
Peer reviewing is a central component in the scientific publishing process. We present the first public dataset of scientific peer …

The Effect of Different Writing Tasks on Linguistic Style: A Case Study of the ROC Story Cloze Task
A writer’s style depends not just on personal traits but also on her intent and mental state. In this paper, we show how variants …

Automatic selection of context configurations for improved (and fast) class-specific word representations
This paper is concerned with identifying contexts useful for training word representation models for different word classes such as …

Story Cloze Task: UW NLP System
This paper describes University of Washington NLP’s submission for the Linking Models of Lexical, Sentential and Discourse-level …

Symmetric Patterns and Coordinations: Fast and Enhanced Representations of Verbs and Adjectives
State-of-the-art word embeddings, which are often trained on bag-of-words (BOW) contexts, provide a high quality representation of …

Symmetric Pattern Based Word Embeddings for Improved Word Similarity Prediction
We present a novel word level vector representation based on symmetric patterns (SPs). For this aim we automatically acquire SPs (e.g., …

How Well Do Distributional Models Capture Different Types of Semantic Knowledge?
In recent years, distributional models (DMs) have shown great success in representing lexical semantics. In this work we show that the …

Minimally Supervised Classification to Semantic Categories using Automatically Acquired Symmetric Patterns
Classifying nouns into semantic categories (e.g., animals, food) is an important line of research in both cognitive science and natural …
Authorship Attribution of Micro-Messages
Work on authorship attribution has traditionally focused on long texts. In this work, we tackle the question of whether the author of a …
Learnability-based Syntactic Annotation Design
There is often more than one way to represent syntactic structures, even within a given formalism. Selecting one representation over …

Neutralizing Linguistically Problematic Annotations in Unsupervised Dependency Parsing Evaluation
Dependency parsing is a central NLP task. In this paper we show that the common evaluation for unsupervised dependency parsing is …
