TangoBERT: Reducing Inference Cost by using Cascaded Architecture
Abstract
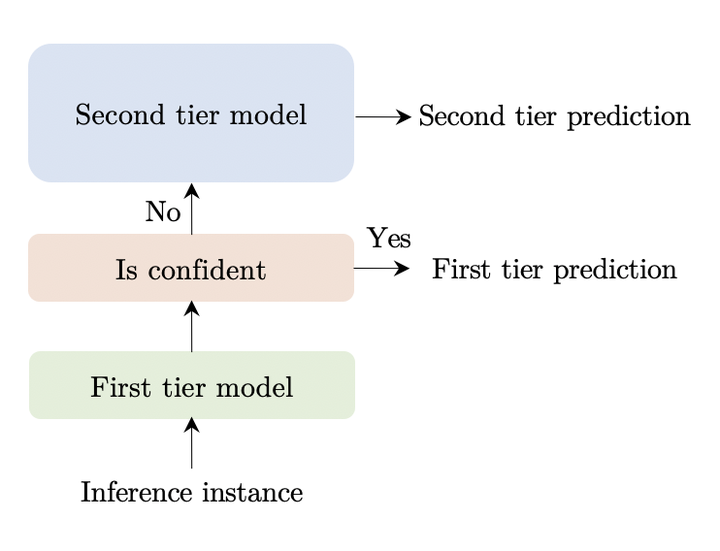
The remarkable success of large transformer-based models such as BERT, RoBERTa and XLNet in many NLP tasks comes with a large increase in monetary and environmental cost due to their high computational load and energy consumption. In order to reduce this computational load in inference time, we present TangoBERT, a cascaded model architecture in which instances are first processed by an efficient but less accurate first tier model, and only part of those instances are additionally processed by a less efficient but more accurate second tier model. The decision of whether to apply the second tier model is based on a confidence score produced by the first tier model. Our simple method has several appealing practical advantages compared to standard cascading approaches based on multi-layered transformer models. First, it enables higher speedup gains (average lower latency). Second, it takes advantage of batch size optimization for cascading, which increases the relative inference cost reductions. We report TangoBERT inference CPU speedup on four text classification GLUE tasks and on one reading comprehension task. Experimental results show that TangoBERT outperforms efficient early exit baseline models; on the the SST-2 task, it achieves an accuracy of 93.9% with a CPU speedup of 8.2x.