Read, Look or Listen? What’s Needed for Solving a Multimodal Dataset
Abstract
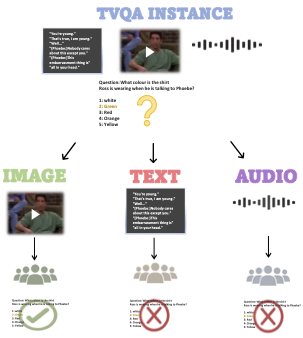
The prevalence of large-scale multimodal datasets presents unique challenges in assessing dataset quality. We propose a two-step method to analyze multimodal datasets, which leverages a small seed of human annotation to map each multimodal instance to the modalities required to process it. Our method sheds light on the importance of different modalities in datasets, as well as the relationship between them. We apply our approach to TVQA, a video question-answering dataset, and discover that most questions can be answered using a single modality, without a substantial bias towards any specific modality. Moreover, we find that more than 70% of the questions are solvable using several different single-modality strategies, e.g., by either looking at the video or listening to the audio, highlighting the limited integration of multiple modalities in TVQA. We leverage our annotation and analyze the MERLOT Reserve, finding that it struggles with image-based questions compared to text and audio, but also with auditory speaker identification. Based on our observations, we introduce a new test set that necessitates multiple modalities, observing a dramatic drop in model performance. Our methodology provides valuable insights into multimodal datasets and highlights the need for the development of more robust models.