News Coverage
Abstract
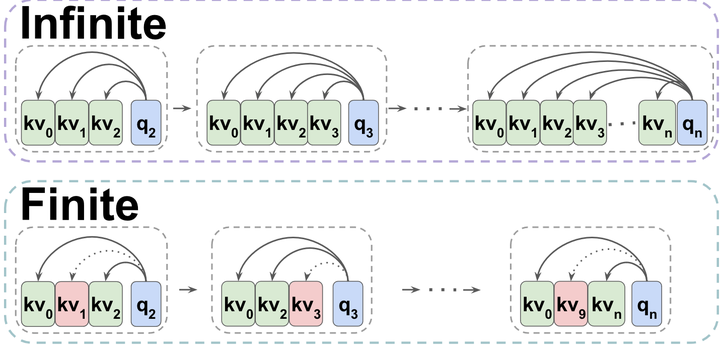
Transformers are considered conceptually different from the previous generation of state-of-the-art NLP models—recurrent neural networks (RNNs). In this work, we demonstrate that decoder-only transformers can in fact be conceptualized as unbounded multi-state RNNs—an RNN variant with unlimited hidden state size. We further show that transformers can be converted into bounded multi-state RNNs by fixing the size of their hidden state, effectively compressing their key-value cache. We introduce a novel, training-free compression policy—Token Omission Via Attention (TOVA). Our experiments with four long range tasks and several LLMs show that TOVA outperforms several baseline compression policies. Particularly, our results are nearly on par with the full model, using in some cases only 1⁄8 of the original cache size, which translates to 4.8X higher throughput. Our results shed light on the connection between transformers and RNNs, and help mitigate one of LLMs’ most painful computational bottlenecks - the size of their key-value cache. We publicly release our code.