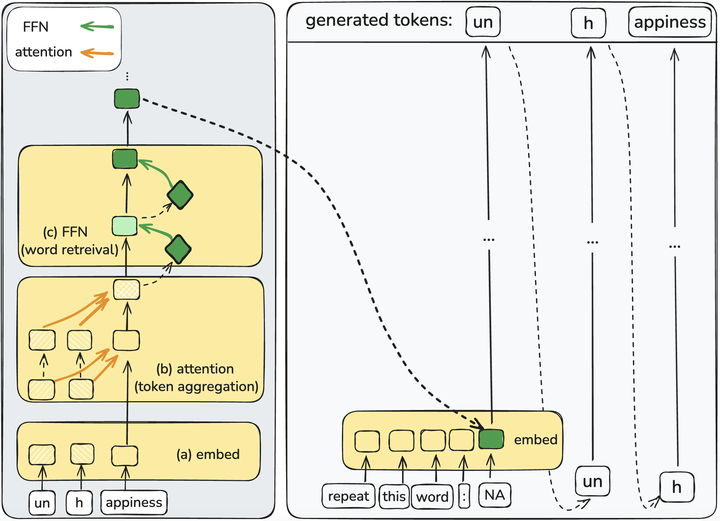
Abstract
Natural language is composed of words, but modern LLMs process sub-words as input. A natural question raised by this discrepancy is whether LLMs encode words internally, and if so how. We present evidence that LLMs engage in an intrinsic detokenization process, where sub-word sequences are combined into coherent word representations. Our experiments show that this process takes place primarily within the early and middle layers of the model. They also show that it is robust to non-morphemic splits, typos and perhaps importantly—to out-of-vocabulary words: when feeding the inner representation of such words to the model as input vectors, it can ‘understand’ them despite never seeing them during training. Our findings suggest that LLMs maintain a latent vocabulary beyond the tokenizer’s scope. These insights provide a practical, finetuning-free application for expanding the vocabulary of pre-trained models. By enabling the addition of new vocabulary words, we reduce input length and inference iterations, which reduces both space and model latency, with little to no loss in model accuracy.