Abstract
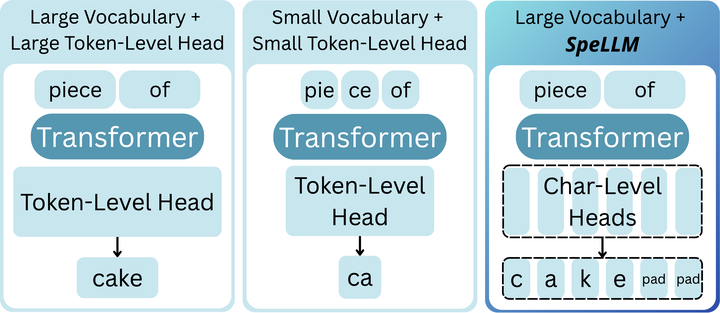
Scaling LLM vocabulary is often used to reduce input sequence length and alleviate attention's quadratic cost. Yet, current LLM architectures impose a critical bottleneck to this procedure: the output projection layer scales linearly with vocabulary size, rendering substantial expansion impractical. We propose SpeLLM, a method that decouples input and output vocabularies by predicting character-level strings through multiple output heads. In SpeLLM, each of the k linear heads predicts a single character simultaneously, enabling the model to represent a much larger output space using smaller, independent linear heads. We present a self-distillation approach for converting a standard LLM to a SpeLLM. Our experiments with four pre-trained LLMs show their SpeLLM variants achieve competitive performance on downstream tasks while reducing runtime by 5.1% on average across models. Our approach provides a potential avenue for reducing LLM costs, while increasing support for underrepresented languages and domains.