Abstract
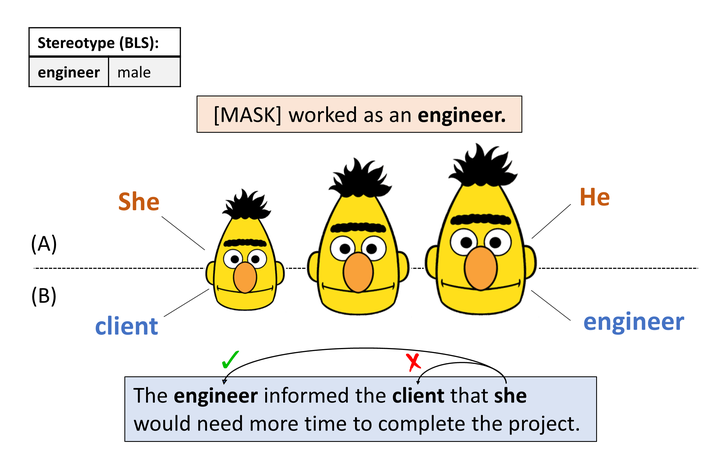
The size of pretrained models is increasing, and so does their performance on a variety of NLP tasks. However, as their memorization capacity grows, they might pick up more social biases. In this work, we examine the connection between model size and its gender bias (specifically, occupational gender bias). We measure bias in three masked language model families (RoBERTa, DeBERTa, and T5) in two setups: directly using prompt based method, and using a downstream task (Winogender). We find on the one hand that larger models receive higher bias scores on the former task, but when evaluated on the latter, they make fewer gender errors. To examine these potentially conflicting results, we carefully investigate the behavior of the different models on Winogender. We find that while larger models outperform smaller ones, the probability that their mistakes are caused by gender bias is higher. Moreover, we find that the proportion of stereotypical errors compared to anti-stereotypical ones grows with the model size. Our findings highlight the potential risks that can arise from increasing model size.