Attend First, Consolidate Later: On the Importance of Attention in Different LLM Layers
Abstract
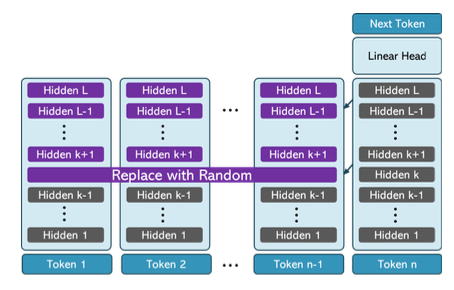
In decoder-based LLMs, the representation of a given layer serves two purposes: as input to the next layer during the computation of the current token; and as input to the attention mechanism of future tokens. In this work, we show that the importance of the latter role might be overestimated. To show that, we start by manipulating the representations of previous tokens; e.g. by replacing the hidden states at some layer k with random vectors. Our experimenting with four LLMs and four tasks show that this operation often leads to small to negligible drop in performance. Importantly, this happens if the manipulation occurs in the top part of the model—k is in the final 30-50% of the layers. In contrast, doing the same manipulation in earlier layers might lead to chance level performance. We continue by switching the hidden state of certain tokens with hidden states of other tokens from another prompt; e.g., replacing the word “Italy” with “France” in “What is the capital of Italy?”. We find that when applying this switch in the top 1⁄3 of the model, the model ignores it (answering “Rome”). However if we apply it before, the model conforms to the switch (“Paris”). Our results hint at a two stage process in transformer-based LLMs: the first part gathers input from previous tokens, while the second mainly processes that information internally.